

çok fazla uğraşmadım terminalden çalışıyor. kullanmak için azda olsa teknik bilgi gerekli
örnek :
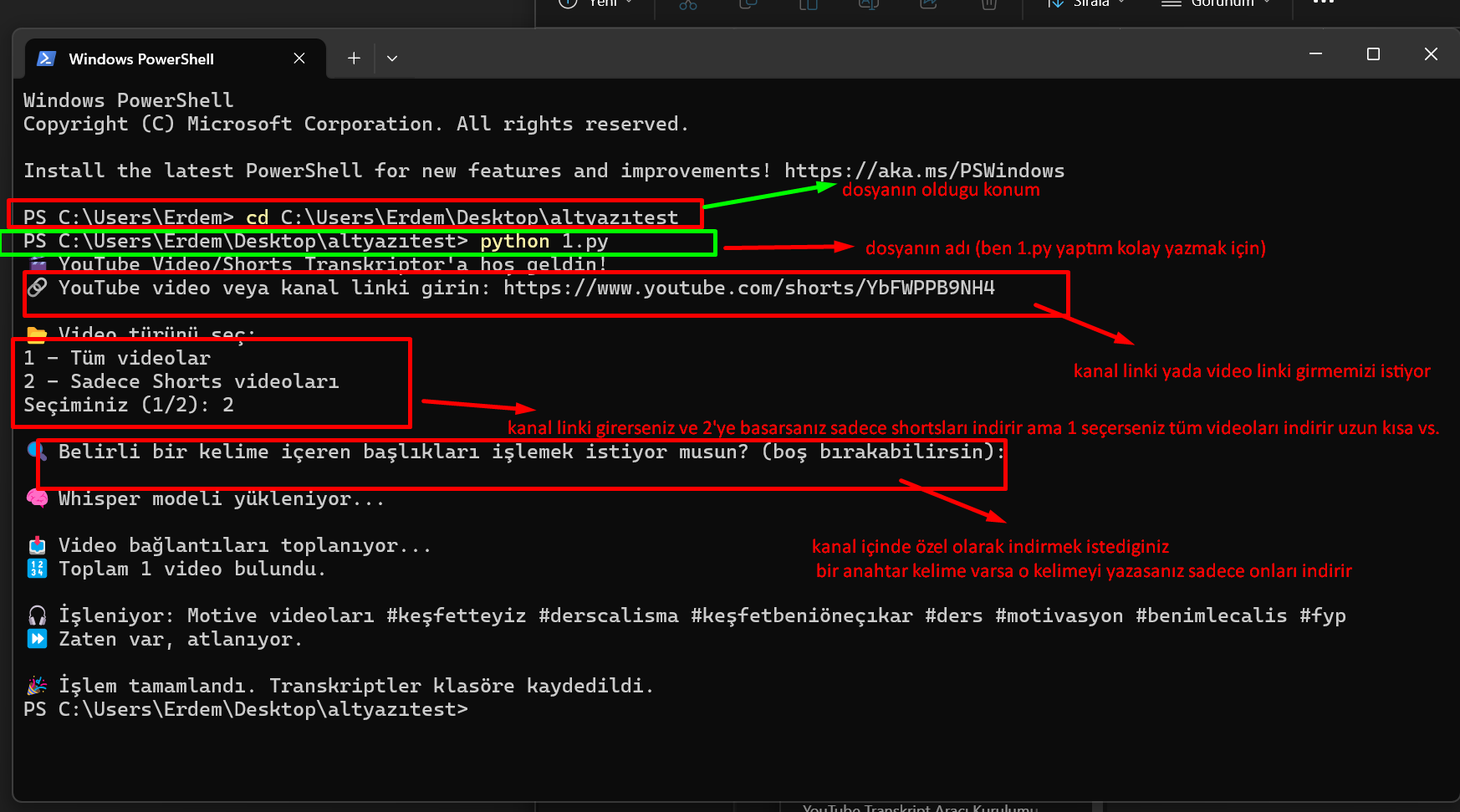
https://www.youtube.com/shorts/YbFWPPB9NH4 bu videoyu yazıya çevirdim
çıktı
Hedefi koyuyorsun, başarıya gitmek istiyorsun. Süreç başlıyor. Zorluluk başladığında ya da sabredemediğinde ya da sonuç alamadığında bahane üretmeye başlıyorsun ve vazgeçiyorsun. Ve senin o hayalini kurduğun şeyi başka birileri kesinlikle başarır. Kendine başarmak için şans bile alamıyorsun. Başarı nedir biliyor musunuz arkadaşlar? Başarı, zaman ve sabır kavramının birleşimidir.
✅ GEREKENLER
1. Python yüklü olmalı.
2. FFMPEG
3. Gerekli programları kurmak için terminale şu komutları yaz:
Bunları sırasıyla Komut İstemcisi (CMD) veya Terminal penceresine yaz:
pip install git+https://github.com/openai/whisper.git pip install yt-dlp pip install torch
🛠️ Programı Nasıl Çalıştıracağım?
- Aşağıdaki kodu txt dosyasına yazın ve dosya adını uzantısı 1.py olarak kaydedin
- 1.py dosyasını masaüstüne koy
- CMD'yi aç ve masaüstüne git: (cd desktop)
- Kodu çalıştır (python 1.py)
import subprocess
import whisper
import os
# 🎯 Kullanıcıdan veri al
print("🎬 YouTube Video/Shorts Transkriptor'a hoş geldin!")
# 1. Kanal ya da tekil video linki
url = input("🔗 YouTube video veya kanal linki girin: ").strip()
# 2. Tüm videolar mı, sadece Shorts mı?
print("\n📂 Video türünü seç:")
print("1 - Tüm videolar")
print("2 - Sadece Shorts videoları")
choice = input("Seçiminiz (1/2): ").strip()
# Linki dönüştür
if "channel" in url and choice == "2" and "/shorts" not in url:
url += "/shorts" # Shorts sekmesini ekle
# 3. Başlık filtresi isteğe bağlı
filter_keyword = input("\n🔍 Belirli bir kelime içeren başlıkları işlemek istiyor musun? (boş bırakabilirsin): ").strip().lower()
# Klasörleri oluştur
output_dir = "shorts_audio"
txt_dir = "shorts_transcripts"
os.makedirs(output_dir, exist_ok=True)
os.makedirs(txt_dir, exist_ok=True)
# Whisper modeli yükle
print("\n🧠 Whisper modeli yükleniyor...")
model = whisper.load_model("medium")
# Tek video mu, çoklu video mu karar ver
if "watch?v=" in url:
# 🎯 Tek video modu
print("\n🎧 Tek video işleniyor...")
# Başlık al
title_result = subprocess.run([
"yt-dlp", "--get-title", url
], capture_output=True, text=True)
title = title_result.stdout.strip()
video_id = url.split("watch?v=")[-1]
if filter_keyword and filter_keyword not in title.lower():
print("⚠️ Başlık filtreye uymuyor, işlem yapılmadı.")
else:
safe_title = title.replace(":", "-").replace("?", "").replace("/", "-")
audio_path = os.path.join(output_dir, f"{safe_title}.mp3")
txt_path = os.path.join(txt_dir, f"{safe_title}.txt")
if os.path.exists(txt_path):
print("⏩ Zaten var, atlanıyor.")
else:
subprocess.run([
"yt-dlp",
"-x", "--audio-format", "mp3",
"-o", audio_path,
url
])
result = model.transcribe(audio_path)
with open(txt_path, "w", encoding="utf-8") as f:
f.write(result["text"])
print(f"✅ Kaydedildi: {txt_path}")
else:
# 🎯 Playlist/Kanal modu
print("\n📥 Video bağlantıları toplanıyor...")
result = subprocess.run([
"yt-dlp",
"--flat-playlist",
"--extractor-args", "youtube:player_client=web",
"-i", "--print", "%(title)s|%(id)s",
url
], capture_output=True, text=True)
videos = [line.strip().split("|") for line in result.stdout.strip().split("\n") if "|" in line]
print(f"🔢 Toplam {len(videos)} video bulundu.\n")
for title, video_id in videos:
if filter_keyword and filter_keyword not in title.lower():
continue
print(f"🎧 İşleniyor: {title}")
safe_title = title.strip().replace(":", "-").replace("?", "").replace("/", "-")
audio_path = os.path.join(output_dir, f"{safe_title}.mp3")
txt_path = os.path.join(txt_dir, f"{safe_title}.txt")
if os.path.exists(txt_path):
print("⏩ Zaten var, atlanıyor.")
continue
subprocess.run([
"yt-dlp",
"-x", "--audio-format", "mp3",
"-o", audio_path,
f"https://www.youtube.com/watch?v={video_id}"
])
result = model.transcribe(audio_path)
with open(txt_path, "w", encoding="utf-8") as f:
f.write(result["text"])
print(f"✅ Kaydedildi: {txt_path}")
print("\n🎉 İşlem tamamlandı. Transkriptler klasöre kaydedildi.")